
Quelle: Gerd Altmann / Pixabay
: Methodik
WIE SIND WIR VORGEGANGEN?
Wir betrachten die Verknüpfung von Twitteraccounts untereinander als ‚Soziales Netzwerk‘. Die Soziale Netzwerkanalyse (SNA) ist ein Forschungsansatz, der soziale Phänomene anhand der Beziehungen der Objekte untereinander beschreibt (und weniger aufgrund der individuellen Eigenschaften einzelner Phänomene). Sie betrachtet primär die Stellung von Objekten in Relation zu anderen. Im Rahmen von diskurslinguistisch orientierten Social-Media-Analysen zielt die SNA darauf ab, Nutzernetzwerke anhand bestehender Beziehungen oder getätigter Interaktionen induktiv zu beschreiben. Dabei werden die Objekte eines Netzwerkes (hier die User der rechten Twittersphäre) als 'Knoten' abgebildet, und die Beziehungen, die zwischen ihnen bestehen, als 'Kanten'. Unser Datensatz umfasst ca. 7700 Knoten (User) und insgesamt ca. 750 000 Kanten (Folgebeziehungen).
Um im sich daraus ergebenden Netzwerk unterschiedliche Communities identifizieren zu können, mussten einige Analyseschritte vollzogen werden:
- Eine erste räumliche Ordnung im Netzwerk entsteht, indem (vereinfach gesagt) algorithmisiert eine Abstoßung zwischen allen Knoten (Accounts) hergestellt wird. Knoten werden also so verteilt, dass möglichst große Abstände zwischen ihnen bestehen. Reduziert wird diese Abstoßung durch vorliegende Kanten (Folgebeziehungen): Diese sorgen für eine Anziehung zwischen den beteiligten Knoten. Es entsteht so ein Netzwerk, in dem die Accounts, die sich untereinander häufig folgen, nahe beieinander positioniert werden.
- Modularitätsklassen: Im nächsten Schritt wurde das gesamte Netzwerk durch einen weiteren Algorithmus in Gruppen eingeteilt, die jeweils untereinander eng vernetzt sind. Diese Gruppen werden als ‚Modularitätsklassen‘ bezeichnet. In unserem Fall entsprechen diesen Modularitätsklassen Twitter-Accounts, die sich (überdurchschnittlich oft) gegenseitig folgen. Da zwar nicht für jeden Einzelfall, aber als Tendenz in der Masse angenommen werden kann, dass Folgebeziehungen zwischen Accounts signalisieren, dass die verbundenen Profile hinsichtlich ihrer Interessen und Präferenzen übereinstimmen, können so auch politische Communities identifiziert werden. Im Ergebnis zeigen sich sieben relevante Klassen, die politische User-Communities beschreiben. Um eine aussagekräftige Visualisierung zu ermöglichen, wurden die Knoten und Kanten des Netzwerkes entsprechend ihrer Modularitätsklasse eingefärbt.
- Sichtung dominanter Accounts in den Modularitätsklassen: Um die nun identifizierten Communities näher beschreiben zu können, wurden die in den jeweiligen Gruppen dominanten (reichweitenstärksten) Accounts manuell gesichtet und hinsichtlich erkennbarer politischer Zuordnungen analysiert. Wir unterstellen dabei, dass die Accounts mit den meisten Followern in einer Gruppe für diese auch am aussagekräftigsten hinsichtlich ihrer politischen Ausrichtung sind (wir gehen also davon aus, dass User tendenziell mehrheitlich den Accounts folgen, mit denen sie auch politisch große Übereinstimmungen haben). Die Reichweite kann als Eingangsgrad eines Accounts in einer Modularitätsklasse erfasst werden, also in der Anzahl der weiteren User einer Klasse, die ihm folgen. Um eine erste Kategorisierung vornehmen zu können, wurden für alle Klassen (mindestens) die 10 reichweitenstärksten Accounts gesichtet (d.h. konkret die eigene Kurzbiographie der Profile sowie die Postings der aktuellen Timeline) und hinsichtlich politischer Aussagen oder thematischer Vorlieben festgehalten. Auf diesem Wege konnten die Klassen politisch kategorisiert werden.
- Größenvergleich der Communities: Nachdem die per Modulklassenberechnung identifizierten Communities in einem ersten Schritt klassifiziert wurden, geht es nun darum, eine Einschätzung der Reichweite der unterschiedlichen Gruppen zu ermöglichen und so auch den (potenziellen) Einfluss auf die gesamte rechte Twittersphäre einschätzen zu können. Dazu sind zwei Werte besonders relevant: Einerseits interessiert uns natürlich die Verteilung der absoluten Größen der verschiedenen Communities (gemessen in Knoten / Accounts, die den jeweiligen Klassen zugerechnet werden). Zusätzlich betrachten wir auch die durchschnittliche Reichweite der Accounts der unterschiedlichen Klassen, um eine Einschätzung zu ermöglichen, wie weit diese über die eigene Community hinaus sichtbar sind und andere User mit ihrem Content erreichen können. Die Reichweite kann über den durchschnittlichen Eingangsgrad (=Anzahl der Follower in unserem Netzwerk) bezogen auf das Gesamtkorpus ermittelt werden. Die folgende Abbildung zeigt beide Werte für die verschiedenen Modularitätsklassen:
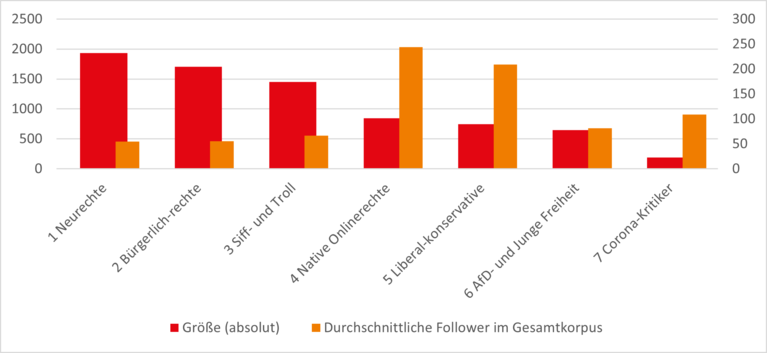
Quelle: Re-DiSS
- Beim Größenvergleichs der Communities fällt zunächst auf, dass die neurechte Community mit 1931 Accounts die größte Klasse in unserem Korpus bildet. Das war nicht zu erwarten, da unsere Vorannahmen eher davon ausgingen, dass die Neue Rechte eher einen mittelbaren Einfluss auf die Social-Media-Diskurse hat, indem ihre Ideen von anderen Gruppierungen rezipiert und adaptiert werden. Tatsächlich bildet die Modularitätsklasse um neurechte Akteure aus dem Umfeld des Institutes für Staatspolitik und der Zeitschrift Sezession die zahlenmäßig größte Community im gesamten Korpus. Dies zeigt eine dominante Stellung der Neuen Rechten in der rechten Twittersphäre. Relativiert wird dieser Befund durch die vergleichsweise geringe durchschnittliche Followeranzahl, die die Accounts der neurechten Community im Gesamtkorpus haben. Man kann daher vereinfacht gesprochen sagen, dass es sich zwar um eine sehr große Gruppe handelt, die aber über den Kreis der eigenen Mitglieder hinaus nur einen beschränkten Einfluss entfalten kann und wenig rezipiert wird. Das gilt auch für das Bürgerlich-rechte Lager und ebenso für Siff- und Trolltwitter (wobei hier zu erwarten gewesen ist, dass es sich um eine eher geschlossene Gruppierung handelt). Auffällig sind hier auch die Native Onlinerechte und die Liberal-Konservativen, die trotz deutlich geringer Anzahl sehr hohe durchschnittliche Followerzahlen haben. Hier muss angenommen werden, dass die typischen User dieser Gruppen insbesondere in die jeweils andere Klasse eine hohe Reichweite haben (siehe zur Vernetzung der Klassen untereinander auch unten). Das ändert aber nichts an der Feststellung, dass die User dieser beiden Communities, die weniger klar politischen Strömungen außerhalb von Social-Media zugeordnet werden können, in der rechten Twittersphäre über die eigene Bubble hinaus beachtliche Sichtbarkeit aufweisen. Im Hinblick auf die Kern-AfD zeigt sich hier, dass ihre Reichweite deutlich geringer ist, als häufig angenommen: Sowohl die absolute Größe des Milieus, als auch die durchschnittlichen Followerzahlen sind deutlich geringer, als erwartet.
- Vernetzung der Communities: Abschießend bleibt die Frage zu klären, ob sich im Hinblick auf die Vernetzung der Communities untereinander erkennen lässt, welche Gruppen in einem engeren Austausch stehen, und welche kaum Berührungspunkte aufweisen. Hierzu haben wir für alle Klassen berechnet, wie viele Folgebeziehungen zu jeweils allen anderen Klassen bestehen. Dabei wurden interne Followings (also Folgebeziehungen in der eigenen Klasse) nicht berücksichtigt. Die verbleibende Verbindungsanzahl wurde in Relation zur Anzahl der Accounts der beiden beteiligten Klassen gesetzt. Der so ermittelte Wert gibt also einfacher gesprochen an, wie häufig die Mitglieder einer Klasse a Accounts einer Klasse b folgen und umgekehrt. Hohe Werte zeigen somit eine enge Vernetzung zwischen zwei Klassen an, niedrige Werte entstehen, wenn nur ein geringer Austausch zwischen zwei Klassen besteht. Die Ergebnisse sind unten in den Steckbriefen der verschiedenen Communities als Netzdiagramm visualisiert. Auffällig ist hierbei beispielsweise, dass die neurechte Community vergleichsweise stark mit Siff- und Trolltwitter verschränkt ist. Es steht zu vermuten, dass hier ein Resonanzraum besteht, in dem neurechte Vorstellungen in einem subkulturellen und für junge Menschen prinzipiell attraktiven Umfeld verbreitet werden, das für die klassischen Öffentlichkeitsformen der Neuen Rechten (Bücher, Zeitschriften, Vortragsveranstaltungen) kaum zugänglich ist. Ein weiterer auffälliger (aber nach den bisherigen Ausführungen nicht mehr überraschender) Befund besteht in der extrem engen Verschränkung der Klassen 4 und 5 untereinander. Dies unterstreicht die Vermutung, dass sich weniger um klar abgegrenzte Communities handelt, sondern vielmehr ein Kontinuum zwischen beiden Klassen besteht, das keine klare Trennung zulässt.
- Keywords: Um präzisere Aussagen über dominante Themen und politische Präferenzen zu ermöglichen, wurden für die verschiedenen Modularitätsklassen Keyword-Analysen durchgeführt. Keyword-Analysen sind etablierte Verfahren der Korpuslinguistik. Bei Keyword-Analysen wird die Verteilungshäufigkeit von Ausdrücken in zwei Korpora miteinander verglichen, um so die – relativ zum Vergleichskorpus – statistisch überdurchschnittlich oft in einem Korpus auftauchenden Ausdrücke bzw. Schlüsselwörter zu ermitteln. Neben dem Untersuchungskorpus, dessen Keywords ermittelt werden sollen, kommen Vergleichskorpora zum Einsatz. In unserem Fall verwendeten wir jeweils Subkorpora als Untersuchungskorpus, die alle Tweets umfassen, deren Autoren einer bestimmten Modularitätsklassen angehören. Als Vergleichskorpus wurden die Tweets aller anderen Autoren unseres User-Korpus verwendet. Dies ermöglicht die Ausdrücke zu ermitteln, die für eine bestimmte Modularitätsklasse im Vergleich zu allen anderen Klassen besonders typisch sind. Die Keyword-Analysen wurden mit dem Korpus-Analysetool CorpusExplorer durchgeführt. Die Keyword-Listen der verschiedenen Klassen wurden manuell bereinigt, z.B. um vorkommende Namen von Twitteraccounts (nicht jedoch um die Namen realer Personen). Zusätzlich wurden nur Keywords gezählt, deren Bedeutung eine politische Relevanz im untersuchten Diskursausschnitt erkennen lässt: So wurden Ausdrücke wie 'T-Shirt' oder 'Serie' nicht weiter betrachtet, Ausdrücke wie 'Schutzmaske' vor dem Hintergrund der Relevanz im Kontext der Corona-Pandemie sehr wohl. Die Ergebnisse wurden weiterhin so gefiltert, dass nur Keywords, die mindestens 30-mal im jeweiligen Untersuchungskorpus vorkommen, berücksichtigt werden. In den Community-Steckbriefen sind jeweils die 10 signifikantesten Keywords aufgelistet.
Welche Daten verwenden wir?
Die Grundlage für die Analyse besteht in einem Datensatz, der ca. 7700 Twitteraccounts erfasst. Ziel der Zusammenstellung war, die deutschsprachige Twittersphäre möglichst vollständig abzubilden. Dazu sind wir mehrstufig vorgegangen: Um eine möglichst breite Grundlage zu schaffen, wurden Accounts, die sich dem rechten Spektrum klar zuordnen lassen oder von denen wir annehmen können, dass sie eine relevante Reichweite unter rechten Twitterusern haben, gesammelt. Diese Sammlung umfasst z.B. mit der AfD oder ihren Funktionsträger:innen verbundene Accounts, aber auch Autor:innen rechter Publikationen oder parteilich ungebundene Institutionen. Weiter wurden Accounts in die Liste aufgenommen, bei denen eine Verbindung zu rechten Organisationen wie der (ehemaligen) Identitären Bewegung oder vergleichbaren Gruppierungen besteht. Auch Accounts (z.B. von Journalist:innen), bei denen wir annehmen konnten, dass sie eine signifikante Reichweite unter Rechten haben, wurden hier berücksichtigt – und zwar ohne, dass wir damit eine Aussage darüber treffen, ob diese Accounts selbst tatsächlich ‚rechts sind‘. Die so zusammengestellte Liste von ca. 300 Accounts bietet die Grundlage für die Erfassung der rechten Twittersphäre, ohne damit eine Beurteilung der politischen Ausrichtung einzelner Accounts zu verbinden.
Von dieser Sammlung ausgehend wurden alle Follower erfasst, die mindestens einem dieser Accounts folgen. Damit sollte einerseits eine größere Datenbasis erreicht werden, andererseits sollen somit auch die Gefahr subjektiver Voreingenommenheit reduziert werden. Die Minimalbedingung lautet, dass ein Account mindestens einem der von uns manuell zusammengestellten Accounts folgen muss, um bei der Analyse berücksichtigt zu werden. Im Ergebnis gehen wir davon aus, dass unser Datensatz die deutschsprachige rechte Twittersphäre repräsentativ abbildet. Dabei ist zu beachten, dass nicht alle User, die (vielleicht auch nur einzelnen) rechten Accounts folgen, als ‚rechts‘ betrachtet werden können. Daher sind keineswegs alle in der Analyse berücksichtigten Accounts ‚rechts‘ – aber (praktisch) alle rechten Accounts sind im Korpus abgebildet. Rückschlüsse auf die politische Gesinnung einzelner Profile sind daher nicht möglich.
Grundlage der Analyse der Vernetzung in der rechten Twittersphäre sind die Folgebeziehungen, die zwischen diesen so ermittelten 7700 Accounts bestehen. Diese wurden durch die Twitter-API (die Datenschnittstelle von Twitter) erhoben und technisch so aufbereitet, dass sie mit geeigneter Analysesoftware untersucht und aufbereitet werden können.